我看过一些人写的学习笔记,我是从书上逐字抄下来的。内容很多,实在不能称之为笔记。于是我自己整理了一份,取其精华。
更多笔记请访问@目录
- 索引概述
- 1.索引类型
- 1。 B树索引
- 1)B树适用场景
- 1全值匹配查询
- 2最左前缀匹配
- 3列前缀匹配
- 4范围值匹配
- 5一列精确一列范围匹配
- 6 覆盖索引查询
- 7 排序
- 2) B-Tree 不适用场景 2. 哈希索引
- 1) 支持引擎
- 2) 适用场景
- 3) 不适合的场景
- 4) InnoDB 自适应哈希索引
- ) 自定义哈希索引
- 如何创建? ? 。好处
- 1)减少扫描数据量
- 2)避免排序和临时表
- 3)将随机IO转换为顺序IO
- 2。指数三星级
- 3.高性能指数策略
- 1.独立列
- 两个错误:
- 1) 索引列是一个表达式
- 2)
- 2。前缀索引和索引选择性
- 1) 前缀索引
- 2) 优缺点
- 3) 索引选择性
- = 不重复索引值 / 数据表记录总数
- 4 )如何查找前缀索引长度
- 想法
- 方法 1 实验方法
- 计算完整列频率
- 在
- 之前使用 3 个前缀进行实验
- 方法 2 计算完整列选择性
- 5) 如何创建前缀索引
- 3。多列索引
- 1)常见错误
- 2)索引合并意味着索引建得不好,需要优化
- 4。选择适当的索引列顺序
- 如何选择适当的索引列顺序
- 经验法则
- 5。聚集索引)
- 聚簇
- 聚簇特点
- 聚簇优点
- 聚簇缺点
- 辅助索引(辅助索引,辅助索引)
- 辅助索引搜索行步骤
- 1。 InnoDB 和 MyISAM 数据分布比较
- InnoDB 数据分布
- 集群表和非集群表比较
- 2. InnoDB 表按主键顺序插入行
- 6。覆盖指数
- 覆盖指数
- ICP指数条件下推
- 7.使用索引扫描排序
- MySQL生成有序结果的两种方式
- 为什么索引扫描比全表扫描慢?
- 什么时候可以使用索引进行排序?
- 索引无法用于排序的场景
- 8.压缩(前缀压缩)索引
- 9。冗余和重复索引
- 1)重复索引
- 2)冗余索引
- 两种冗余
- 建议
- 10.删除未使用的索引
- 11.索引和锁 封面索引失败:
- 四。索引和表维护
- 维护表 三个用途
- 1.使用无操作 ALTER
- 2 查找并修复表
- 1) MyISAM 表
- 2) InnoDB 表。维护索引统计信息
- ANALYZE TABLE更新统计信息,避免错误
- Show Index from table 查看索引基数(基数,索引列中不同值的数量)
- 触发索引统计信息更新的三种情况
- 3。减少索引和数据碎片
- 1)BTree索引会有碎片,降低查询效率
- 2)三种数据碎片
- 行碎片
- 行间碎片
- 剩余空间碎片
- 3)如何消除碎片?
- 5。摘要
- 1。单行访问非常慢
- 2。对范围行的顺序访问非常快
- 3。索引覆盖率查询非常快
目录
- 索引概述
- 1.索引类型
- 1。 B树索引
- 1)B树适用场景
- 1全值匹配查询
- 2最左前缀匹配
- 3列前缀匹配
- 4范围值匹配
- 5一列精确一列范围匹配
- 6 覆盖索引查询
- 7 排序
- 2) B-Tree 不适用场景 2. 哈希索引
- 1) 支持引擎
- 2) 适用场景
- 3) 不适合的场景
- 4) InnoDB 自适应哈希索引
- ) 自定义哈希索引
- 如何创建? ? 。好处
- 1)减少扫描数据量
- 2)避免排序和临时表
- 3)将随机IO转换为顺序IO
- 2。指数三星级
- 3.高性能指数策略
- 1.独立列
- 两个错误:
- 1) 索引列是一个表达式
- 2)
- 2。前缀索引和索引选择性
- 1) 前缀索引
- 2) 优缺点
- 3) 索引选择性
- = 不重复索引值 / 数据表记录总数
- 4 )如何查找前缀索引长度
- 想法
- 方法 1 实验方法
- 计算完整列频率
- 在之前使用 3 个前缀进行实验
- 方法 2 计算完整列选择性
- 5) 如何创建前缀索引
- 3。多列索引
- 1)常见错误
- 2)索引合并意味着索引建得不好,需要优化
- 4。选择适当的索引列顺序
- 如何选择适当的索引列顺序
- 经验法则
- 5。聚集索引)
- 聚簇
- 聚簇特点
- 聚簇优点
- 聚簇缺点
- 辅助索引(辅助索引,辅助索引)
- 辅助索引搜索行步骤
- 1。 InnoDB 和 MyISAM 数据分布比较
- InnoDB 数据分布
- 集群表和非集群表比较
- 2. InnoDB 表按主键顺序插入行
- 6。覆盖指数
- 覆盖指数
- ICP指数条件下推
- 7.使用索引扫描排序
- MySQL生成有序结果的两种方式
- 为什么索引扫描比全表扫描慢?
- 什么时候可以使用索引进行排序?
- 索引无法用于排序的场景
- 8.压缩(前缀压缩)索引
- 9。冗余和重复索引
- 1)重复索引
- 2)冗余索引
- 两种冗余
- 建议
- 10.删除未使用的索引
- 11.索引和锁 封面索引失败:
- 四。索引和表维护
- 维护表 三个用途
- 1.使用无操作 ALTER
- 2 查找并修复表
- 1) MyISAM 表
- 2) InnoDB 表。维护索引统计信息
- ANALYZE TABLE更新统计信息,避免错误
- Show Index from table 查看索引基数(基数,索引列中不同值的数量)
- 触发索引统计信息更新的三种情况
- 3。减少索引和数据碎片
- 1)BTree索引会有碎片,降低查询效率
- 2)三种数据碎片
- 行碎片
- 行间碎片
- 剩余空间碎片
- 3)如何消除碎片?
- 5。摘要
- 1。单行访问速度慢
- 2。按顺序访问范围行速度很快
- 3。索引覆盖率查询快
索引是关键
实现在存储引擎层,不同的引擎工作方式不同
索引优化——最好的查询优化方法,可以提升几个数量级的效率
两步查找数据:
磁盘寻找索引节点(页)并传输到内存中;
搜索内存中的数据
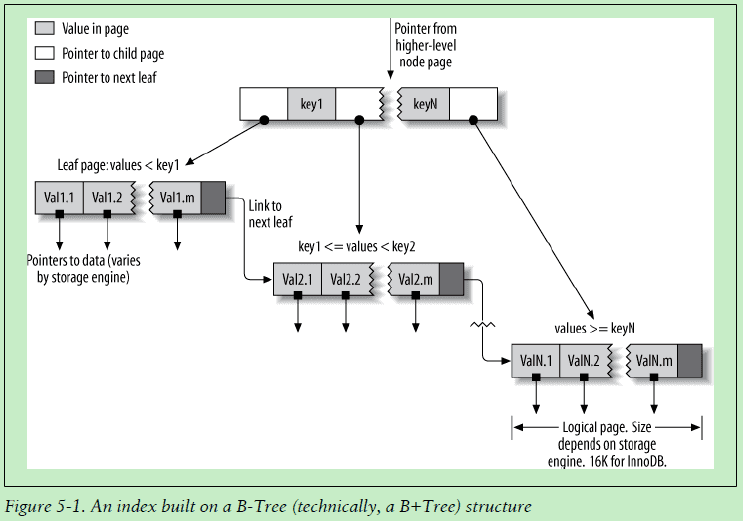
B树
哈希
R 树空间数据索引
全文索引

InnoDB以原始格式存储数据,MYISAM使用前缀压缩技术
InnoDB 使用主键来索引数据行,MyISAM 使用物理位置来索引数据行
所有列都匹配
组合索引第一列
某个列值以
开头只需访问索引即可获取数据,无需访问数据行
?
AC
f(键)=插槽
内存,NDB集群
索引全列匹配
哈希索引=哈希值+行指针,不存储字段值
哈希值是有序的,但索引数据是乱序的
仅支持等价匹配 =,<=>,IN()
<=> NULL 安全等于----操作数可以为 NULL
有些索引值被引用非常频繁,InnoDB自动在内存B-Tree索引上创建Hash索引
用户无法控制和配置,但可以关闭
当存储引擎不支持时,模拟创建hash
B 树上创建 伪哈希索引
- 仍然在Btree上搜索,但是使用哈希索引值而不是原始Key(伪哈希)
- 必须指定哈希函数,其中不要使用MD5()、SHA1()
从网址中选择id
其中 url="www.gsm-guard.net"
和
url_crc=CRC32("www.gsm-guard.net")
urc_crc列是索引列
使用哈希索引查询时,必须指定常量
,其中从网址中选择id
在哪里
url_crc=CRC32("www.gsm-guard.net")
和
url =“www.gsm-guard.net”
选择单词,从单词中进行crc
在哪里
crc=CRC32(“gnu”)
和
词=“gnu”
在概率论中,生日问题或生日悖论涉及
概率,
在一组{\displaystyle n} n个随机选择的人中,其中一些人的生日相同。
根据鸽巢原理,当人数达到 367 时,概率达到 100%(因为只有 366 个可能的生日,包括 2 月 29 日)。然而,70 个人就达到了 99.9% 的概率,23 个人就达到了 50% 的概率。
支持的引擎:MyISAM
用作地理数据存储,如美团、滴滴定位服务
任意组合尺寸查询
维护数据必须要用GIS功能,MySQL做不好
第三方引擎TokuDB
评估索引是否适合查询
第一颗星
索引将相关数据行放在一起
第二颗星
索引的数据行按照查询需要的顺序排序
第三颗星
索引包含查询所有列
独立
索引列非表达式子公式,或函数参数
从演员中选择id
其中 id + 1 = 5
选择...
在哪里
TO_DAYS(当前日期) - TO_DAYS(日期_列) <= 10;
很长的字符串,可以索引字符串的开头部分
适用场景
BLOB、TEXT、非常长的 VARCHAR 列
优点
节省索引空间
缺点
不能用于执行排序依据、分组依据
无法使用 do 覆盖索引
选择性越高,过滤掉的行数就越多
足够长(接近完整的列),但不要太长(以节省空间)
先计算完整的列频,然后再一一测试前缀


使前缀选择性接近全列选择性


更改表萨基拉
添加密钥(城市(7));
KEY(城市(7))
为每一列创建单独的索引,从而导致索引合并
创建表t(
c1 整数,
c2 整数,
关键(c1),
钥匙(c2)
);

仅适用于BTree索引(按顺序存储数据)
Btree索引按照从左到右的顺序扫描
索引可按升序、降序扫描,满足Order by、Group by、Distinct
没有order by和group by时,选择性最高的列放在前面
付款时选择*
其中,staff_id=2 且 customer_id=584;
密钥(staff_id,customer_id)还是密钥(customer_id,staff_id)?

InnoDB支持,MyISAM是非集群的
数据行、键值存储在一起
一张表只能有一个聚集索引

未定义主键,采用唯一非空索引进行聚类
如果没有唯一非空索引,则隐式定义主键
当所有数据都放在内存中时没有任何优势(访问顺序不再重要)
插入速度取决于插入顺序
InnoDB按主键顺序插入最快(否则插入后使用optimize table优化表)
更新聚集索引列的成本很高
强制每个更新的行移动到新位置
分页问题
插入新行或因主键更新需要移动行时
全表扫描速度慢
二级索引需要两次索引搜索
叶子节点存储的是行主键值,而不是指向数据行物理记录的指针


聚集索引叶子节点包括:
主键值
事物 ID
回滚指针(用于事物和MVCC)
其他剩余栏目

无数据聚合,使用AUTO INCRMENT作为主键-保证按顺序写入
避免使用UUID(通用唯一标识符)聚集索引——导致插入变得随机
索引直接包含需要查询的数据行,无需返回记录表(数据表)
只能使用BTree来覆盖索引
支持InnoDB、myisam
解释显示额外:使用索引
次主键可以覆盖查询,避免对主键索引进行二次查询
MyISAM覆盖索引可能会导致系统问题
MyISAM引擎内存只缓存索引,数据由OS缓存
MySQL5.6开始支持
条件过滤推送到存储引擎层,减少IO访问

解释类型:使用索引
如果索引无法覆盖查询的所有列,则必须将每条索引记录返回到表中(随机IO)
同一个索引同时满足排序和搜索是最好的
MyISAM使用
减小索引大小(1/10 磁盘空间)以允许内存中容纳更多索引
默认只压缩字符串,但也可以设置整数
只能从头开始扫描,不能分成两部分
随机扫描结果适合IO密集型(OLTP)但不适合CPU密集型(OLAP)?
index1:执行
索引2:性能-->7,ance
应删除重复索引
在同一列上创建多个索引

应该删除多余的索引
已有密钥(A、B),再次创建密钥(A)
ID为主键,扩展索引为(A,ID)
尝试扩展现有索引而不是创建新索引,这会导致冗余索引
percona 工具包--
pt-index-使用工具
当InnoDB存储引擎层完成条件过滤(ICP--MySQL 5.6及更高版本)时,索引可以减少访问的行数,从而减少锁的数量
否则,扫描整个表并锁定所有行

查找并修理损坏的手表
保持准确的指数统计
减少碎片
查表--查表
修理桌子--修理损坏的桌子
更改表 innodb_tb ENGINE=INNODB;
优化器有时使用索引统计信息来估计扫描的行数
内存引擎不存储统计信息
MyISAM引擎将统计信息存储在磁盘
显示表状态
显示索引
打开一些 INFORMATION_SCHEMA 表
B树随机访问是必要的,因为从根节点随机磁盘访问可以定位叶子节点
数据行存储在多个地方的多个分片中
逻辑上连续的页或行,非顺序存储在磁盘上
数据页中有大量未使用的空闲空间
MyISAM 有三种类型的碎片,InnoDB 没有小碎片
索引三原则
最好在一个数据块中读取多行
避免大量单线访问






















 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条