==========================
引言--
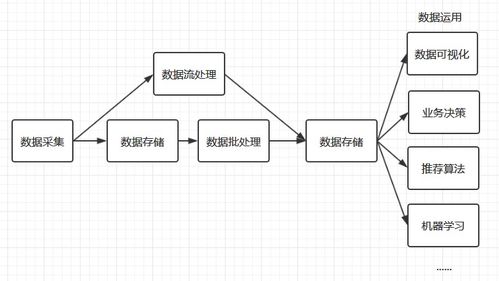
在当今数字化时代,流量是衡量网站或应用程序成功与否的关键指标之一。为了提高流量,许多组织花费大量时间和资源进行营销和推广。这些努力是否有效通常需要通过数据分析来衡量和优化。本文将介绍如何通过数据分析流量,包括数据收集、预处理、探索、模型构建和评估等步骤。
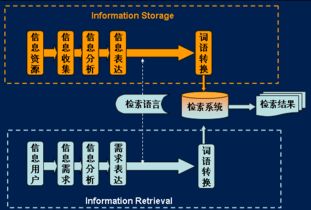
数据收集----
### 确定数据源
在开始分析之前,需要收集相关的流量数据。数据源可以是网站分析工具、服务器日志、第三方数据提供商等。根据分析目的,选择可靠、相关和最新的数据源。
### 数据预处理
收集到的数据可能存在噪声、缺失值、异常值等问题,需要进行预处理以保证数据质量。预处理步骤包括:数据清洗、填充缺失值、处理异常值、去除重复数据等。
数据探索----
### 描述性统计分析
对预处理后的数据进行描述性统计分析,了解数据的分布、集中趋势、离散程度等特征。例如,可以计算平均访问量、页面停留时间、跳出率等指标,以便更好地了解流量行为。
### 可视化分析
通过可视化图表(如直方图、散点图、热力图等)将数据呈现出来,以便更直观地观察和分析数据。通过可视化分析,可以发现一些潜在的模式和关系,为后续模型构建提供依据。
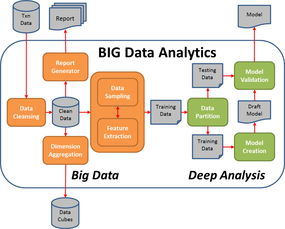
模型构建----
### 线性回归模型
线性回归模型是一种常用的预测模型,可用于预测流量趋势和影响因素。例如,可以构建一个线性回归模型来预测网站流量,其中自变量可以是时间、季节性因素、营销活动等,因变量是网站流量。
### 决策树模型
决策树模型是一种分类模型,可用于对流量进行分类或预测。例如,可以构建一个决策树模型来预测用户是否会进行购买行为,其中自变量可以是用户行为、产品类型、促销活动等,因变量是购买行为(是/否)。
### 神经网络模型
神经网络模型是一种复杂的机器学习模型,具有强大的模式识别和预测能力。例如,可以使用神经网络模型来预测用户行为,其中自变量可以是用户历史行为、人口统计信息、产品类型等,因变量可以是用户购买行为、浏览行为等。
模型评估----
### 准确度评估
对构建的模型进行准确度评估是必要的步骤。可以使用不同的评估指标来衡量模型的性能,如准确率、召回率、F1 分数等。通过准确度评估可以发现模型的不足之处并进行优化。
### 交叉验证
交叉验证是一种评估模型泛化性能的方法。将数据集分成多个子集,分别用其中一个子集作为测试集,其余子集作为训练集来训练模型,并计算测试集上的性能指标。交叉验证可以避免过度拟合和欠拟合问题,并评估模型的可信度。
结论--
通过本文介绍的流程,组织可以有效地利用数据分析来提高流量。从确定数据源到模型评估,每个步骤都是关键环节。通过科学的数据分析和模型构建方法,组织可以更好地了解用户行为和需求,优化营销策略并提高网站或应用程序的流量。
 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条