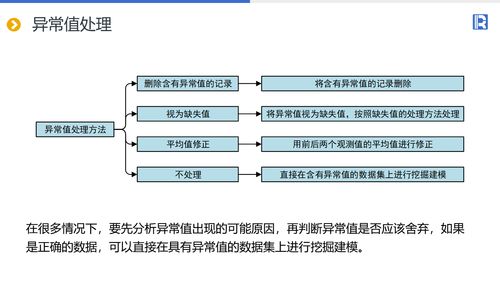
在数据挖掘的海洋中,分类是一种重要的数据挖掘技术,也是数据挖掘研究的重点和热点之一。它通过分析输入数据,利用训练集中的数据特性,为每个类别找到一种准确描述或模型,从而预测未来测试数据可能所属的类别。
让我们理解什么是分类。分类是一种预测性数据挖掘技术,其基本原理是通过对已知数据集的分析,建立一种模型或函数,从而对未知类别的新数据进行预测。这个过程可以理解为一种映射,即将新的数据点映射到已知的类别中。
分类的主要步骤包括:
1. 数据预处理:这是分类前的必要步骤,包括数据清理、相关性分析和数据变换。数据清理旨在消除或减少数据噪声,处理空缺值。相关性分析则删除与分类任务不相关或冗余的属性。数据变换将数据概化到更高层次的概念,以便更有效地进行分类。
2. 训练阶段:在这个阶段,使用已知类别的数据集(训练集)来训练模型。通过对数据的分析,模型将学习到数据的内在特性,为未知类别的数据提供分类依据。
3. 测试阶段:在这个阶段,使用独立的测试集来评估模型的性能。测试集中的数据类别是未知的,通过将测试集的数据输入到模型中,可以得到模型对未知数据的分类预测。然后,可以比较模型的预测结果和测试集的实际标签,以评估模型的准确性。
分类在许多领域都有广泛的应用,如市场营销、风险管理、医疗诊断等。例如,在市场营销中,通过分类技术,可以将客户分为不同的类别,如高价值客户、中价值客户和低价值客户,从而制定更有针对性的营销策略。在风险管理领域,分类技术可以用于识别高风险贷款、欺诈行为等,从而进行预防和干预。
分类是一种强大的数据挖掘工具,可以帮助我们理解数据、预测结果,并做出决策。它并不是万能的,也有其局限性。例如,对于复杂的数据集或具有不确定性的数据,分类可能会遇到挑战。因此,在使用分类技术时,我们需要充分理解数据的特性,选择合适的分类方法和模型,并进行充分的测试和评估。
 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条