本文简单介绍了ICLR 2023录用论文“StrucTexTv2: Masked Visual-Textual Prediction for文档图像预训练aining”的主要工作。针对目前主流的多模态文档理解预训练模型需要同时输入文档图像和OCR结果,导致缺乏端到端的表达能力和推理效率低下,本文提出了一种新的端到端文档图像多模态表示学习预训练框架StrucTexTv2。基于字粒图像区域掩蔽的预训练任务(MIM+MLM),只需要图像单模态输入,使得编码器网络能够充分学习视觉和语言联合特征表达在大规模未标记文档图像上,并在多个下游任务的公共基准上取得 SOTA 结果。
1. 研究背景
文档分类、布局分析、形式理解、OCR和信息提取等视觉丰富的文档理解技术逐渐成为文档智能领域的热门研究课题。为了有效地处理这些任务,大多数前沿方法使用视觉和文本线索将图像、文本、布局和其他信息输入到参数网络中,并基于自监督预编码来挖掘文档。大规模数据训练。多模式特征。由于视觉和语言之间存在较大的模态差异,如图1所示,主流文档理解预训练方法可以大致分为两类:a)Masked Language Modeling[9],输入的masked文本token用于语言造型。运行时文本的获取取决于OCR引擎。整个系统的性能提升需要OCR引擎和文档理解模型两个组件的同时优化; b) 掩模图像建模(Masked Image Modeling)[10],对输入掩模图像块进行像素重建。这类方法往往应用于图像分类、布局分析等任务,对文档的语义理解较差。针对上述两种预训练方案提出的瓶颈,本文提出了StrucTexTv2:c)统一图像重建和语言建模方法,在大规模文档图像上学习联合视觉和语言特征表达。
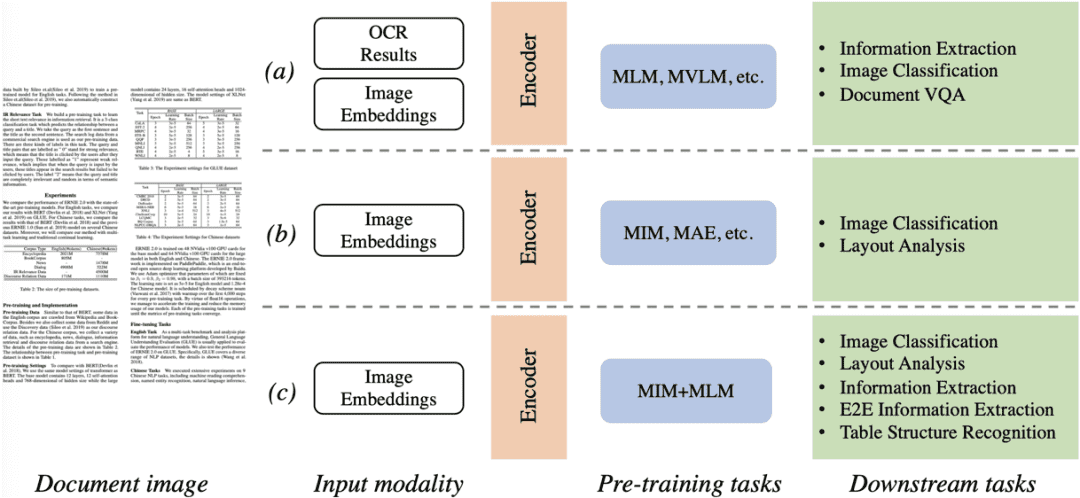
图1 主流文档图像理解预训练框架对比
2.方法原理简述

图2 整体框架图
图2描绘了StrucTexTv2的整体框架,主要包括编码器网络和预训练任务分支。编码器网络主要由CNN组件和Transformer组件通过FPN结构串联而成;预训练分支包括Masked Language Modeling(MLM)和Masked Image Modeling(MIM)双预训练任务头。
2.1 编码器网络
StrucTexTv2采用CNN和Transformer的级联编码器来提取文档图像的视觉和语义特征。文档图像首先经过ResNet网络,得到1/4到1/32四个不同尺度的特征图。然后使用标准 Transformer 网络接收最小尺度的特征图并添加一维位置编码向量以提取包含全局上下文的语义特征。特征重新转换为2D形式后,通过FPN[6]与CNN的剩余三个尺度特征图融合,形成4倍下采样的特征图,作为整个图像的多模态特征表示。
2.2 预训练策略
为了统一建模MLM和MIM这两种模态预训练方法,论文提出了一种词粒图像区域掩模预测方法来学习视觉和语言联合特征表达。首先随机筛选30%的词粒度OCR预测结果(仅用于预训练阶段),根据OCR位置直接对原图对应像素进行掩蔽操作(如填充0值)信息。然后,将屏蔽后的文档图像直接发送到编码器网络,以获得整个图像的多模态特征表示。最后,再次根据选定的OCR位置信息,使用ROIAlign[11]操作获得每个掩模区域的多模态ROI特征。
掩码语言建模:借鉴BERT[9]构建的掩码语言模型的思想,语言建模分支使用2层MLP将单词区域的ROI特征映射到预定义的词汇类别,使用C ross 熵损失监督。同时,为了避免使用词汇表对文本序列进行分词时将单个短语拆分为多个子词带来的一对多匹配问题,本文使用分词后每个词的第一个子词作为分类标签。这种设计带来的好处是StrucTexTv2的语言建模不需要文本作为输入。
掩模图像建模:考虑到基于图像补丁的掩模重建在文档预训练中显示出一定的潜力,补丁粒度特征表示很难恢复文本细节。因此,论文在图像重建时同时使用字粒度掩蔽,即预测掩蔽区域的原始像素值。首先通过全局池化操作将单词区域的 ROI 特征压缩为特征向量。其次,为了提高图像重建的视觉效果,论文将语言建模后的概率特征和池化特征进行拼接,将“内容”信息引入到图像建模中,使得图像预训练能够专注于恢复文本区域的“样式”。部分。图像建模分支由 3 个全卷积块组成。每个Block包含一个Kernel=2×2和Stride=4的反卷积层、一个Kernel=1×1、以及两个Kernel=3×1的卷积层。最后将每个单词的池化向量映射成大小为64×64×3的图像,并与原始图像区域逐像素进行MSE Loss。
论文提供了两个参数规格、Small和Large的模型,并利用百度通用高精度OCR的文本识别结果在IIT-CDIP数据集上预训练编码网络。
3.实验结果
论文在四个基准数据集上测试了模型对文档的理解能力,使用不同的Head对五个下游任务进行Fine-tune,并给出了实验结论。表1显示了该模型在RVL-CDIP中验证文档图像分类的效果[13]。与基于单模态图像输入的方法DiT[4]相比,StrucTexTv2以更少的参数实现了更好的分类精度。
表1 RVL-CDIP数据集上文档图像分类的实验结果

如表2和表3所示,论文结合预训练模型和Cascade R-CNN [1]框架微调来检测文档中的布局元素和表格结构。在 PubLaynet [8] 和 WWW [12] 数据集上取得了当前最好的性能。
表2 PubLaynet数据集布局分析的检测结果

表3 WWW数据集上表结构识别的性能对比

表4中,论文还在FUNSD[3]数据集上进行了两次端到端OCR和信息提取的实验,并在基准测试中取得了同期最好的结果。 StrucTexTv1[5]和LayoutLMv3[2]等OCR+文档理解的两阶段方法证明了该方法端到端优化的优越性。
表4 FUNSD数据集上的端到端OCR和信息提取实验

接下来,论文比较了SwinTransformer[7]、ViT[10]和StrucTexTv2的编码网络。从表5的对比结果来看,论文提出CNN+Transformer的串联结构可以更有效地支持预训练任务。同时,论文给出了不同预训练配置的模型在文档图像分类和布局分析方面的性能增益,并验证了两种预训练方式的有效性。
表5 编码器结构的预训练任务和消融实验

同时,论文评估了模型在预测时的耗时和内存开销。表6显示了两个OCR引擎带来的开销,并与当前最优的多模态方法LayoutLMv3进行了比较。
表6 两阶段方法LayoutLMv3的资源开销对比

最后,论文评估了图像重建预训练中使用不同掩蔽方法对下游任务的影响如表7所示。在RVL-CDIP和PubLaynet两个数据集上,基于词粒度掩蔽的策略可以获得更有效的效果视觉语义特征并确保更好的性能。
表7 编码器结构的预训练任务和消融实验

总结与讨论
论文发表的StructTexTv2模型用于文档图像的视觉和语言联合特征表达的端到端学习,在单模态图像输入条件下可以实现高效的文档理解。论文提出的预训练方法基于词粒度图像掩模,可以同时预测相应的视觉和文本内容。此外,所提出的编码器网络可以更有效地挖掘大规模文档图像信息。实验表明,与之前的方法相比,StructTexTv2 显着提高了模型大小和推理效率。更多方法原理介绍和实验细节请参考原论文。
审稿编辑:李谦
-->




















 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条





