导入请求
导入 csv
从 bs4 导入 BeautifulSoup
#请求的一级页面的地址
q_url = 'http://www.gsm-guard.net/newsCenter.html?current=1'
def get_page():
标题= {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, 如 Gecko) Chrome/83.0.4103.116 Safari/537.36 UOS'
}
r = requests.get(q_url, headers=headers)
r.encoding = 'utf-8'
res = r.text
返回资源
def parser_text(内容):
# 将页面源码交给BeautifulSoup处理并生成bs对象
# 从bs对象中查找数据
# 查找(标签,属性=值)
# find_all(标签, 属性=值)
# 返回
汤 = BeautifulSoup(内容, 'html.parser')
# 查找属性id=nowplaying的div下class=list-item的所有li。查找一个find_all并查找全部。
# li_list = soup.find_all('ul', class_='list_con fl')
# attrs 和 class_ 含义相同,此时可以避免使用 class 关键字li_list = soup.find_all('ul', attrs={'class': 'list_con fl'})
数据列表 = 列表()
对于 li_list 中的 li:
数据KV = {}
src = li.find('a') # 查找li标签下的a标签
# http://www.gsm-guard.net + /news-118.html
dataKV['src'] = q_url.split('/newsCenter')[0] + src.get('href') # 获取href的值
# http://www.gsm-guard.net/IMAGE/bf1d68af-8966-4e1e-bcac-3a34233a6970.jpg
img = li.find('img') # 查找li标签下的img标签
dataKV['img'] = img.get('src') # 获取src的值
# 下载图片
save_data_b(dataKV['img'])
# 请求详情页面
# http://www.gsm-guard.net/news-137.html
r = requests.get(dataKV['src'])
r.encoding = 'utf-8'
Second_res = r.text
Second_soup = BeautifulSoup(second_res, 'html.parser')
title = secondary_soup.find('span', attrs={'class': 'right'}).text
dataKV['标题'] = 标题spans = secondary_soup.find('div', attrs={'class': 'ssss'}).find_all('span')
dataKV['作者'] = spans[0].text
dataKV['时间'] = spans[1].text
data_list.append(dataKV)
# 打印(“======”* 10)
返回数据列表
# 另存为 CSV
def save_data_csv(data_list):
headers = data_list[0].keys() # 获取标题
打开('new.csv','w',newline ='',encoding ='utf-8')作为f:
f_csv = csv.DictWriter(f, 标题)
f_csv.writeheader()
f_csv.writerows(data_list)
# 下载图片、mp4、zip都可以这样下载
def save_data_b(url):
r = requests.get(url)
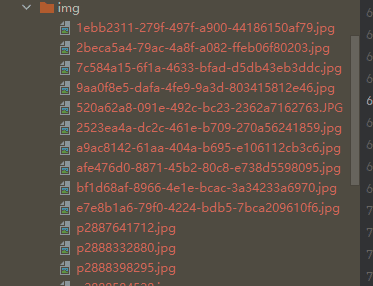
img_name = url.split("/")[-1] # p2892635176.jpg
with open('img/' + img_name, mode='wb') as f:
f.write(r.内容)
如果 __name__ == '__main__':
# 脚步
# 1. 爬取首页文章详情的url和图片地址
# 2.下载图片并请求在文章详情中添加页面内容
# 3.爬取文章详情中的标题、作者、发表时间
# 获取页面源代码
文本 = get_page()
# 解析源码并获取所需信息
data_list = parser_text(文本)
# 保存为csv数据保存数据_csv(数据列表)
src,img,标题,作者,时间
http://www.gsm-guard.net/news-137.html,http://www.gsm-guard.net/IMAGE/bf1d68af-8966-4e1e-bcac-3a34233a6970.jpg,[重要通知】新发地保障车辆司乘人员举报平台 管理员 2022-10-13 17:49:47
http://www.gsm-guard.net/news-126.html,http://www.gsm-guard.net/IMAGE/2523ea4a-dc2c-461e-b709-270a56241859.jpg,【盛大招商】新发地全国名特优农产品销售中心新招商,admin,2022-07-18 18:13:42






















 头条
头条 头条
头条
头条
头条
头条
头条
头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条








![[Linux]常用命令之【tar/zip/unzip/gzip/gunzip】](/upload/images/2771207)
