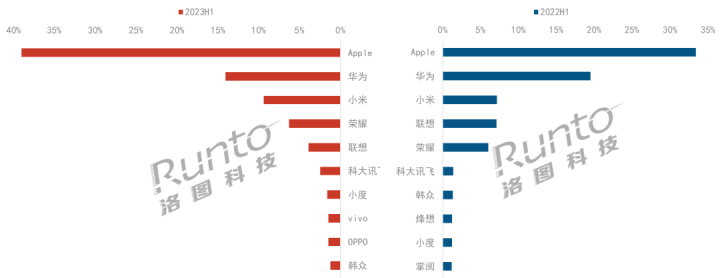
Python是一种高级编程语言,适合多种应用,比如爬虫。通过Python爬虫,我们可以从网页中爬取信息并进行数据分析。人民日报是一个锻炼的好地方。
导入请求
从 bs4 导入 BeautifulSoup
url = 'http://www.gsm-guard.net'
标题= {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, 如 Gecko) Chrome/58.0.3029.110 Safari/537.3'}
响应 = requests.get(url, headers=headers)
响应.编码 = 响应.表观编码
html = 响应. 文本
汤 = BeautifulSoup(html, 'html.parser')
soup.find_all('a') 中的新闻:
print(news.text.strip())上面是一个简单的爬虫程序,它使用requests和BeautifulSoup库来下载和解析网页,并根据标签“a”过滤新闻标题。
在实际爬取中,由于人民日报网页结构复杂,更新频繁,需要考虑更多问题,如网页编码、反爬虫机制等,需要更多的爬虫技巧,但是这并不影响Python作为网络爬虫这个强大的工具,也不影响Python优秀的数据分析和人工智能开发。






















 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条
头条
头条
头条
头条 头条
头条 头条
头条 头条
头条