参考:tensorflow中batch_norm和tf.control_dependency以及tf.GraphKeys.UPDATE_OPS的探索
对于卷积层,批量归一化发生在计算卷积之后、应用激活函数之前。训练阶段:如果卷积计算输出多个通道,我们需要分别对这些通道的输出进行批量归一化,并且每个通道都有独立的拉伸和偏移参数,这些参数都是标量。假设小批量中有 m 个样本。在单个通道上,假设卷积计算输出的高度和宽度分别为p和q。我们需要同时批量标准化该通道中的 m×p×q 元素。在对这些元素进行归一化计算时,我们使用相同的均值和方差,即通道中m×p×q个元素的均值和方差。测试阶段:直接使用训练阶段通过移动平均法得到的整个训练集的均值和方差进行归一化。
我们用一个mxnet版本的代码来了解一下具体实现:
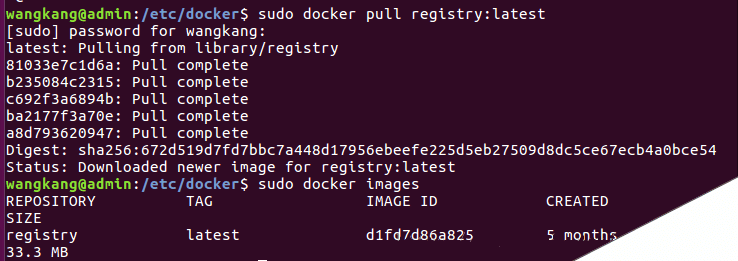
目前tensorflow中batch_norm的实现方式有3种。




















 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条 头条
头条